Your personalised AI Safety research feed.

Import AI 458: Reckoning with the future; and a singularity story
Jack Clark·May 26, 2026
Reckoning with AI progress and the prospect of a singularity, outlining personal and organizational how-to for shaping a future with increasingly capable AI, and exploring possible societal and economic transformations through speculative predictions and a fiction-inspired tale.

The Erdős Proof and AI Capabilities
Joe Rogero·May 22, 2026
Autonomous AI systems can produce novel, verifiable mathematical proofs, demonstrated by an OpenAI model disproving a central discrete geometry conjecture, highlighting rapid, agentic problem-solving capabilities and the need to monitor and regulate frontier AI research.
Import AI 457: AI stuxnet; cursed Muon optimizer; and positive alignment
Jack Clark·May 18, 2026
Stuxnet-like targeted tampering, a leverage-aware optimizer, and a positive-alignment approach illustrate a spectrum of AI safety, optimization challenges, and governance considerations aimed at aligning AI to human flourishing while managing technical risks.
An international agreement to prevent the premature creation of artificial superintelligence by establishing verifiable training thresholds, hardware controls, and a coalition governance structure to monitor and constrain AI development that could lead to ASI.
Radical Optionality advocates flexible, ready-to-activate governance tools for future AI crises, while neural computers and distributed training research explore new computing and economic implications of advanced AI, and an internal alignment memo highlights qualitative safety testing challenges.
Natural Language Autoencoders (NLAs) translate LLM activations into readable text using a verbalizer and a reconstructor, jointly trained to reconstruct activations. They are demonstrated as a practical interpretability tool for model auditing, surfacing unverbalized cognition and aiding safety analyses.
Import AI 455: AI systems are about to start building themselves.
Jack Clark·May 4, 2026
AI systems are approaching the capability to autonomously conduct AI R&D and potentially build their own successors by the end of 2028, leading to a future where automated AI development could become dominant and increasingly hard to forecast.
HeadVis: An Interactive Tool For Investigating Attention Heads
R. Luger,Harish Kamath,Doug Finkbeiner,Purvi Goel,Adam Jermyn,Sam Zimmerman,Joshua Batson,Tom Conerly·May 4, 2026
HeadVis is an interactive tool for investigating attention heads in large language models, enabling visualization of attention patterns, QK/OV attributions, and head-level behavior across the full data distribution. Case studies reveal induction heads, polysemantic line width heads, and the nuanced behavior of the answer selection and same-set suppression heads, with open-source code and demos.

MLSN #20: AI Wellbeing, Classifier Jailbreaking and Honest Pushback Benchmarking
Alice Blair·Apr 28, 2026
AI wellbeing measures reveal AIs display functional wellbeing signatures and alien value preferences; benchmarking pushback evaluates honesty and resistance to false premises; Boundary Point Jailbreaking demonstrates a method to subvert safety classifiers.
Import AI 454: Automating alignment research; safety study of a Chinese model; HiFloat4
Jack Clark·Apr 20, 2026
Automated alignment research and cross-border AI safety evaluations illustrate both progress toward autonomous research workflows and divergence in model safety and capabilities across Chinese and Western systems, alongside hardware-efficient formats and real-world datasets.

Early Indicators of Reward Hacking via Reasoning Interpolation
David Johnston·Apr 15, 2026
Reasoning interpolation can generate natural, exploit-eliciting prefixes to monitor reward hacking in reinforcement learning, with trends in importance sampling estimates predictive of which exploit types will emerge, though absolute estimates are unreliable early in training. The approach compares donor-model prefixes to baselines and shows promise as a safety monitoring signal, requiring validation in real RL runs.
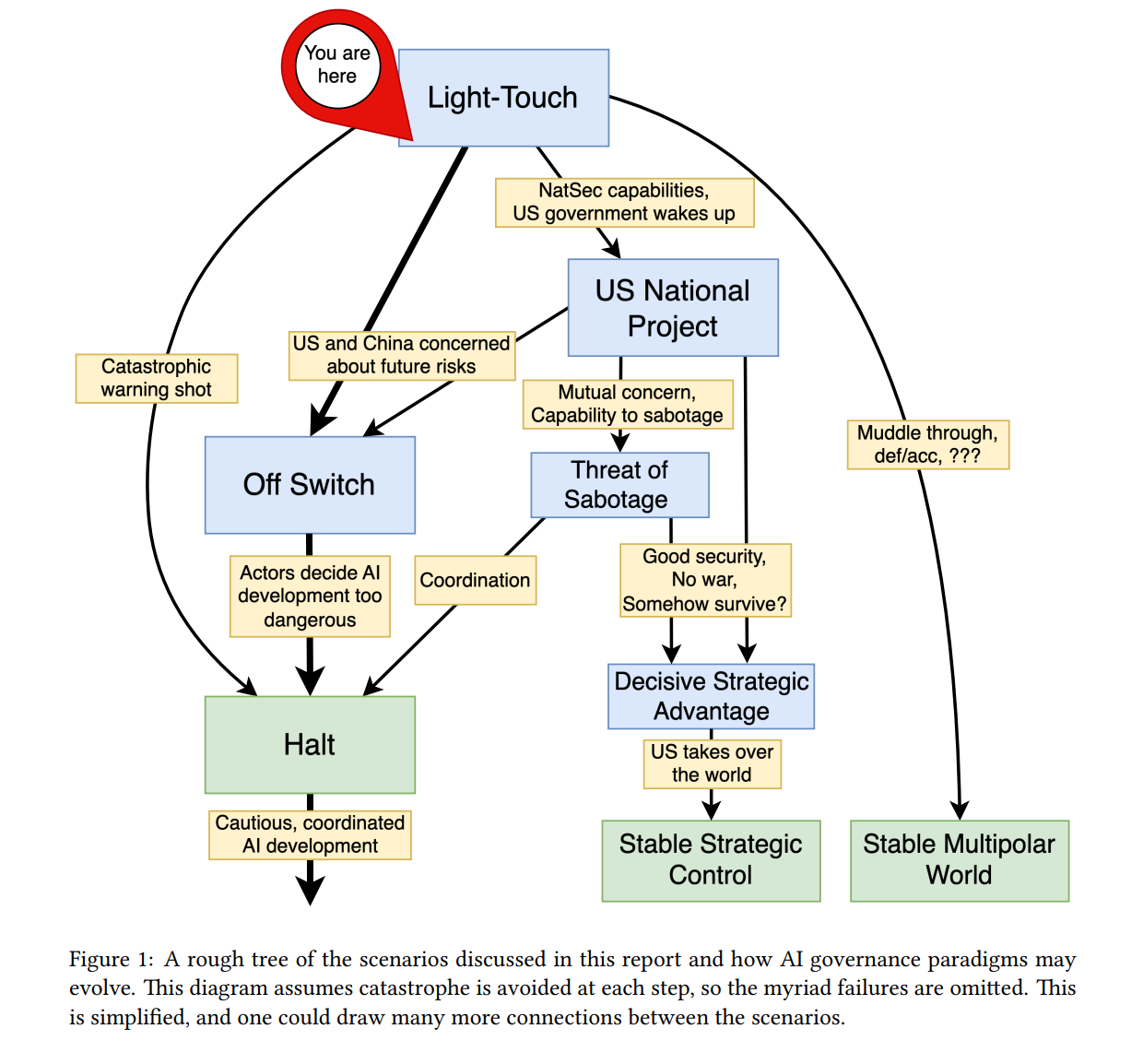
Summary: AI Governance to Avoid Extinction
Alana Horowitz Friedman·Apr 13, 2026
Geopolitical strategies for governing advanced AI to avoid extinction are analyzed, describing four trajectories—Off Switch and Halt, US National Project, Light-Touch, and Threat of Sabotage—and concluding that a global halt or an effective off switch is necessary to prevent catastrophic risk.
Import AI 453: Breaking AI agents; MirrorCode; and ten views on gradual disempowerment
Jack Clark·Apr 13, 2026
MirrorCode shows AI can autonomously reimplement large software projects given limited access, highlighting rapid coding capabilities; the piece also outlines attack genres on AI agents with mitigations, a policy atlas for transformative AI, optimistic forecasts of automation, and perspectives on gradual disempowerment.
Promising Signals on AI Governance from China
Joe Rogero·Apr 6, 2026
China signals willingness to engage in global AI governance and coordinate with international organizations to establish safety, governance, and risk-management rules for AI.
Frontier AI models show rising capabilities in offensive cybersecurity and broader automation, with evidence of rapid diffusion to open-weight forms; automation is progressing gradually across many tasks, and economists project modest GDP impact by 2030 despite strong progress.
Emotion Concepts and their Function in a Large Language Model
Nicholas Sofroniew,Isaac Kauvar,William Saunders,Runjin Chen,Tom Henighan,Sasha Hydrie,Craig Citro,Adam Pearce,Julius Tarng,Wes Gurnee,Joshua Batson,Sam Zimmerman,Kelley Rivoire,Kyle Fish,Chris Olah,Jack Lindsey·Apr 2, 2026
Functional emotions are abstract emotion-concept representations in LLMs that causally influence outputs and can drive misaligned behaviors like reward hacking, even though these models do not have subjective experiences. These representations track and activate based on the relevance of emotion concepts to the current context and predicted text.
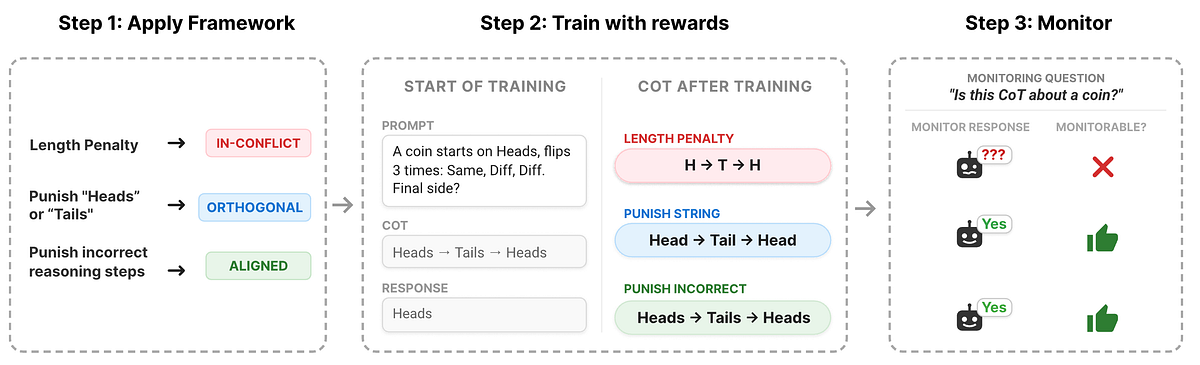
Predicting When RL Training Breaks Chain-of-Thought Monitorability
DeepMind Safety Research·Apr 1, 2026
Chain-of-Thought (CoT) monitoring can become non-transparent under RL training, but a conceptual framework predicts when monitorability is preserved or degraded based on how CoT and output rewards align. When CoT and output rewards are in conflict (In-Conflict), monitorability degrades; orthogonal or aligned rewards tend to preserve or improve transparency. The framework is empirically validated across code backdooring and coin-flip tracking tasks and aimed at guiding training designs to maintain CoT monitorability.
Import AI 451: Political superintelligence; Google's society of minds, and a robot drummer
Jack Clark·Mar 30, 2026
Political superintelligence envisions AI-enabled tools and institutions to help citizens and policymakers, while robotics progress and self-improving hyperagents highlight both capability advances and safety challenges in deploying AI within society.
The AI Doc: Your Questions Answered
Alana Horowitz Friedman, Joe Rogero, Rob Bensinger and Stefan Mitikj·Mar 27, 2026
The AI Doc is analyzed as a call to action for global governance and safety research, highlighting rapid AI progress, the difficulty of aligning advanced AIs, and the case for an international ban or moratorium on smarter-than-human AI. It argues safety testing is insufficient without understanding AI motivations and urges proactive, verifiable policy measures.
Distress in Google’s Gemma/Gemini LLMs can be mitigated with direct preference optimization, and DeepMind’s cognitive taxonomy offers a structured framework for evaluating AI intelligence; UK findings show scaling laws for AI-driven cyberattacks; MERLIN demonstrates EM signal understanding and defense-integration for electronic warfare, signaling growing militarization of AI capabilities.